仮想イベントデータ×PythonでGA4を裏側から理解する|first_visit・セッション・PV・CVRを再現してみた
GA4の数字(ユーザー数・セッション数・PV・CVR)を見ていて、こう感じたことはありませんか?
- 数字は見ているけど「結局、何を数えてるのか」が曖昧
- レポート画面が多くて、どこを見ればいいか迷う
- CVRを見ても、どの入口(ランディングページ)が効いてるのかピンとこない
そこでこの記事では、仮想イベントデータ(first_visit / session_start / page_view / conversion)を自作し、Python(pandas)でGA4の主要指標を再現します。
「GA4の数字=イベントの集計結果」という感覚を、自分の手で腹落ちさせるのがゴールです。
1 なぜ仮想データで練習するのか
1-1 GA4は「イベントの集計結果」だが、画面だけだと腹落ちしづらい
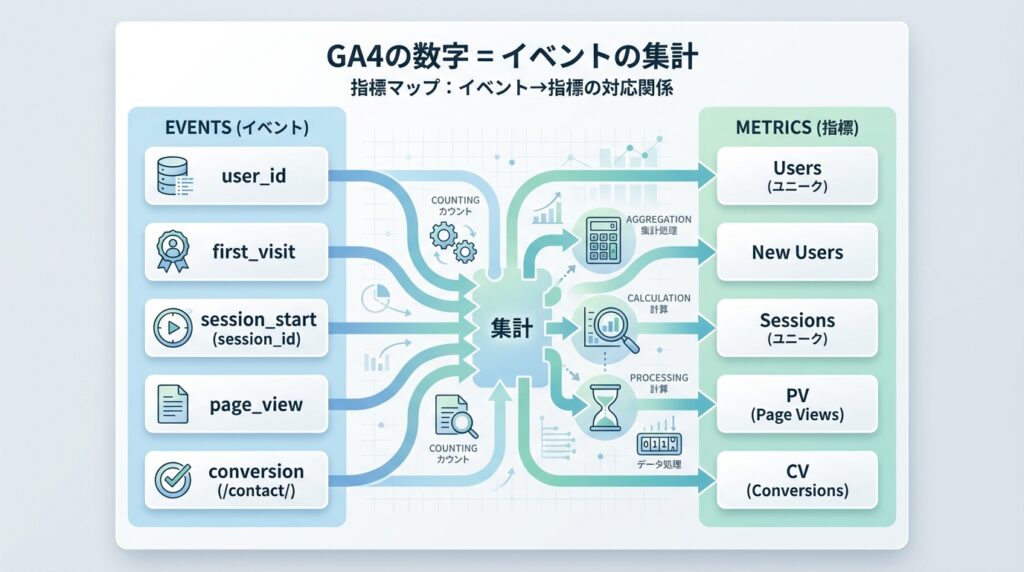
GA4は、もともと「イベント」を記録し、それを集計して指標として見せています。
しかし、GA4のUIは完成されているぶん、裏側の数え方(ロジック)が見えにくいのが難点です。
だからこそ、いったん裏側に戻って、
- イベントログを作る
- 自分で数える
- その数字がGA4のどこに対応するかを確認する
という順番で学ぶと、理解が急に進みます。
1-2 実データが少ないと“検証の練習”ができない(特にCV周り)
小規模サイトほど、CVが少なく、LP別CVRなどがブレて判断しづらいです。
仮想データなら、母数を確保しながら「検証の型」を安全に練習できます。
1-3 仮想データ×Pythonで得られるメリット
- 指標を「自分の言葉」で定義できる(何を数えているか説明できる)
- GA4画面を見たときに「この指標は何の集計か」が想像できる
- 数字を改善アクション(次の打ち手)につなげやすくなる
1-4 この記事のゴール
読了後に、次ができれば成功です。
- ユーザー/新規ユーザー/セッション/PV/LP別CVRをPythonで再現できる
- GA4で「どのレポートで何を見るか」を迷わない
- “入口→成果”で改善の仮説が立てられる
2 仮想イベントデータの設計と作り方
2-1 今回の世界観(さくら整体院+ブログ/直近3ヶ月)
- 対象サイト:さくら整体院+ブログ
- 期間:直近3ヶ月想定
- 最終KGI:新規予約(CV)を増やす
- 主役KPI:初回訪問ベースのランディングページ別CVR
- 施策レイヤー:流入最適化(Organic / Social など)
2-2 今回のイベント設計(GA4の基本イベント+CV)
first_visit:新規ユーザーの起点session_start:セッション開始page_view:ページ閲覧(PVの正体)conversion:/contact/ で発生する予約CVイベント(仮)
2-3 カラム定義(このデータで何が再現できるか)
今回のCSVは次のカラムを持ちます。
event_timestamp:イベントの日時(順序の根拠。LP判定に必須)date:日付(期間集計用)user_id:ユーザー単位の集計session_id:セッション単位の集計event_name:first_visit / session_start / page_view / conversionpage_path:ページ別PV、LP判定に使うchannel_group:Organic / Social / Direct / Referral など
このあとのPython集計は、同じCSVを使って一緒に進めます。
まずは練習用の仮想イベントデータをダウンロードしてください。
- ダウンロード:仮想イベントデータ(CSV)
- 中身:
event_timestamp / user_id / session_id / event_name / page_path / channel_group / date
ダウンロードできたら、次の章で pandasで読み込んで集計していきます。
2-4 ブレ防止の「定義宣言」
本文の途中で迷わないように、ここで定義を固定します。
- 新規ユーザー:
first_visitを持つユーザー - セッション:
session_id(セッション数=session_idユニーク) - PV:
page_view件数 - CV:
conversion(/contact/で発生) - LP:セッション内で最初の
page_viewのpage_path(最小event_timestamp) - 初回訪問ベース:新規ユーザーの最初のセッションのみ対象
3 PythonでGA4の主要指標を再現してみる
準備:CSVを読み込み、分析しやすい形に整える
import pandas as pd
df = pd.read_csv("ga4_virtual_events_sakura_seitaiin_3months.csv")
# 日時型に変換(LP判定などで必須)
df["event_timestamp"] = pd.to_datetime(df["event_timestamp"])
# 必要なら期間で絞る(今回はCSVが3ヶ月想定なので省略してもOK)
# df = df[(df["date"] >= "2025-10-10") & (df["date"] <= "2026-01-09")]
指標1:ユーザー数・新規ユーザー数を再現する
ビジネスの問い
- 直近3ヶ月で「どれくらい人が来たか?」(ユーザー数)
- 「初めて来た人はどれくらいか?」(新規ユーザー数)
- 初回流入チャネル(first touch)はどこが強いか?
Python集計ロジック
- ユーザー数=期間内の
user_idユニーク数 - 新規ユーザー数=
event_name=="first_visit"のuser_idユニーク数 - 初回流入チャネル=
first_visit行のchannel_groupで集計(重複なし)
Pythonコード例
users = df["user_id"].nunique()
new_users = df.loc[df["event_name"]=="first_visit", "user_id"].nunique()
first_touch = (
df[df["event_name"]=="first_visit"]
.groupby("channel_group")["user_id"].nunique()
.sort_values(ascending=False)
)
print(users, new_users)
print(first_touch)
結果(あなたの集計)
- ユニークユーザー数:62
- 新規ユーザー数:42
- 初回流入チャネル(新規ユーザー42の内訳)
- Organic Search 27 / Social 7 / Direct 5 / Referral 3
ミニ対応表(GA4対応の書き込み欄)
- Python:
user_idユニーク /first_visitユーザー - GA4:ユーザー / 新規ユーザー(獲得系)
指標1:ユーザー数・新規ユーザー数(ミニノック4問)
問1(選択式:定義)
Pythonで「新規ユーザー数」を今回の定義で最も正しく再現するのはどれ?
A. user_id のユニーク数
B. event_name=="first_visit" の user_id ユニーク数
C. event_name=="session_start" の件数
D. event_name=="page_view" の件数
解答:B
解説: 今回は「新規ユーザー=first_visitを持つユーザー」と定義しているためです。
問2(記述:重複の理由)
チャネル別ユニークユーザー数を単純に集計すると、合計が全体ユーザー数を超えることがあります。なぜ?(1〜2行)
解答例: 同一ユーザーが期間中に複数チャネルで来訪し、チャネル別集計だと重複計上されるため。
解説: 迷いを減らすには「初回流入(first touch)で1ユーザー1チャネル」に固定します。
問3(実務:読み取り)
新規ユーザー(first touch)が Organic 27、Social 7、Direct 5、Referral 3 でした。
この結果から言えることとして最も妥当なのはどれ?
A. Socialが最重要なのでSEOは不要
B. 新規獲得はOrganic依存が大きく、Socialは補助的に効いている可能性が高い
C. Directが多いので広告が原因
D. Referralが少ないのでサイトが壊れている
解答:B
解説: 新規獲得はOrganicが主力、Socialは一定の補完。ここから「Organicの質(LP別CVR)」と「Socialの再訪(指標2)」を確認すると改善に直結します。
問4(実務:次に見るべきもの)
新規ユーザー数が増えた一方で、予約(CV)が増えません。次に優先して見るべき組み合わせはどれ?
A. PVだけを増やす
B. ランディングページ別CVR(初回訪問ベース)と、流入チャネル別CVR
C. サイトの色変更
D. 直帰率(このデータにはないが、それだけを見る)
解答:B
解説: “獲得(新規)”と“成果(CV)”が結びついているかを確認するには、入口(LP/チャネル)別のCVRが最短です。
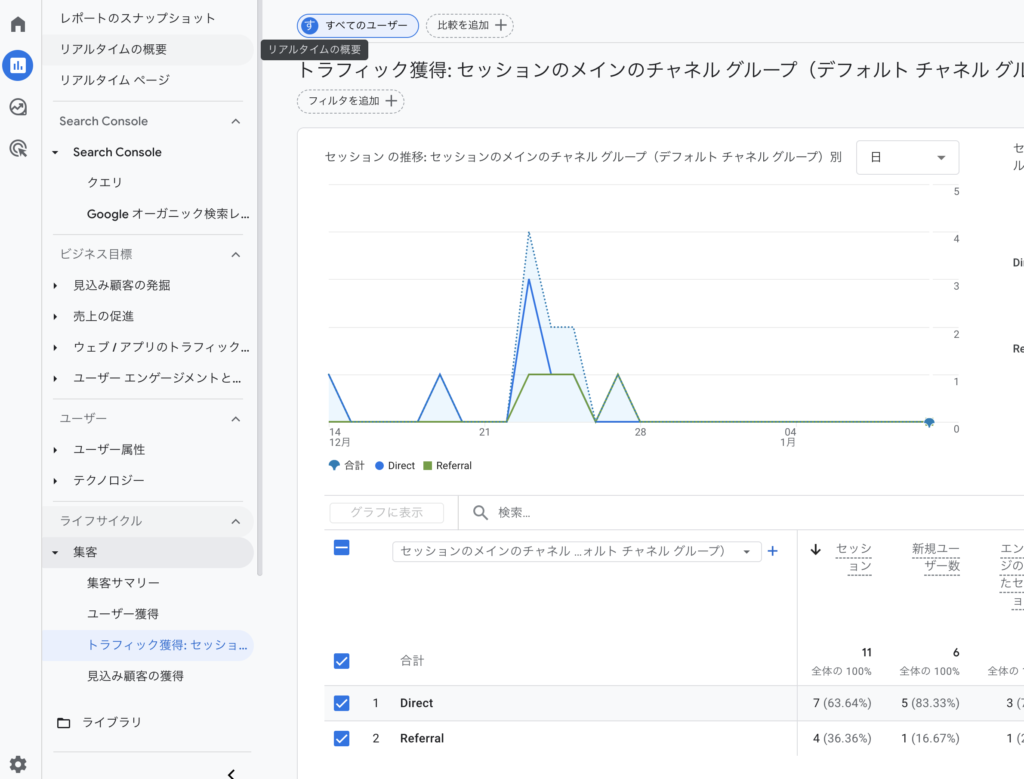
指標2:セッション数・1ユーザーあたりセッション数を再現する
ビジネスの問い
- 1人が何回くらい訪問しているか?(リピートの兆し)
- 初回流入チャネル別に、再訪しやすいユーザー層はあるか?
Python集計ロジック(文章)
- セッション数=
session_idユニーク数 - 1ユーザーあたりセッション数=セッション数 ÷ ユーザー数
- 初回流入チャネル別=first_touchでユーザーを固定し、そのユーザー群のセッション数を集計
Pythonコード例(全体)
sessions = df["session_id"].nunique()
sessions_per_user = sessions / users
print(sessions, sessions_per_user)
Pythonコード例(初回流入チャネル別:B案)
# first_touchチャネル(新規ユーザーのみ)
ft = df[df["event_name"]=="first_visit"][["user_id","channel_group"]].rename(columns={"channel_group":"first_touch_channel"})
# ユーザーにfirst_touchを付与
df2 = df.merge(ft, on="user_id", how="left")
# 新規ユーザー群(first_touchがあるユーザー)のみで、セッション/ユーザー
report = (
df2[df2["first_touch_channel"].notna()]
.groupby("first_touch_channel")
.agg(unique_users=("user_id","nunique"),
total_sessions=("session_id","nunique"))
)
report["sessions_per_user"] = report["total_sessions"] / report["unique_users"]
print(report.sort_values("sessions_per_user", ascending=False))
結果(あなたの集計)
- 訪問回数の平均:1.53(中央値1、最大3)
- 初回流入チャネル別(新規ユーザー群のリピート貢献度)
- Social:1.57
- Organic:1.26
- Direct:1.00
- Referral:1.00
ミニ対応表(GA4対応の書き込み欄)
- Python:
session_idユニーク /sessions ÷ users - GA4:セッション / セッション(またはセッション/ユーザー相当)
指標2:セッション数・1ユーザーあたりセッション数(ミニノック4問)
問1(選択式:定義)
セッション数を最も安定して再現できるのはどれ?
A. event_name=="session_start" の件数
B. session_id のユニーク数
C. user_id のユニーク数
D. event_name=="page_view" の件数
解答:B
解説: セッションは session_id 単位。整合していればAでも同じになりがちですが、Bが基本です。
問2(計算:基礎)
ユーザー数62、セッション数95のとき、1ユーザーあたりセッション数は?(小数第2位)
解答:1.53
解説: 95÷62=1.53。平均訪問回数の目安です。
問3(実務:分布の解釈)
訪問回数別ユーザーが 1回:34、2回:23、3回:5 でした。最も妥当な解釈はどれ?
A. リピートが強いので新規施策は不要
B. 単発訪問が多く、再訪導線(関連記事・CTA・LINE等)に改善余地がある
C. 3回訪問が多いので問題ない
D. セッション数は意味がない
解答:B
解説: 中央値が1回に寄っているため、初回で終わるユーザーが多い。改善するなら「次に読む記事」「予約までの導線」「再訪動機」の設計です。
問4(実務:チャネル別の“質”)
初回流入チャネル別の sessions_per_user が Social 1.57、Organic 1.26 でした。ここから次のアクションとして妥当なのはどれ?
A. Socialは再訪が強い可能性があるので、SNSからの導線(プロフィール/固定投稿/CTA)を整備する
B. Socialは母数が少ないので全て無視する
C. Organicは弱いのでSEO記事を削除する
D. セッション/ユーザーは見ない
解答:A(※ただし母数注意)
解説: Socialが高いのは“関心が続きやすい層”の可能性。ただしサンプルが小さい場合は過信せず、同傾向が続くか確認します。
指標3:PV・ページ別PVを再現する
ビジネスの問い
- どのページがよく見られているか?(人気コンテンツ)
- ブログ記事は読まれているか?(入口候補の発見)
Python集計ロジック(文章)
- PV=
event_name=="page_view"の件数 - ページ別PV=page_viewを
page_pathでcount - 併記:ページ別ユニークユーザー(そのページを見たユーザー数)
Pythonコード例
pv = df[df["event_name"]=="page_view"]
page_pv = (
pv.groupby("page_path")
.agg(pv_count=("event_name","count"),
unique_users=("user_id","nunique"))
.sort_values("pv_count", ascending=False)
)
print(page_pv.head(10))
結果(あなたの集計:TOP10例)
- /contact/ が最も多い
- /menu/、/(トップ)も上位
- ブログ記事では user_engagement、page_view などが上位
ブログ配下に限定(主役へつなぐ)
- ブログ配下総PV:115
- ブログ記事別PVランキング
- /blog/ga4-user-engagement/(23)
- /blog/ga4-page-view/(18)
- /blog/seo-basics/(16) …など
ミニ対応表(GA4対応の書き込み欄)
- Python:page_view件数(Views相当)
- GA4:ページ別の表示回数(Views相当)
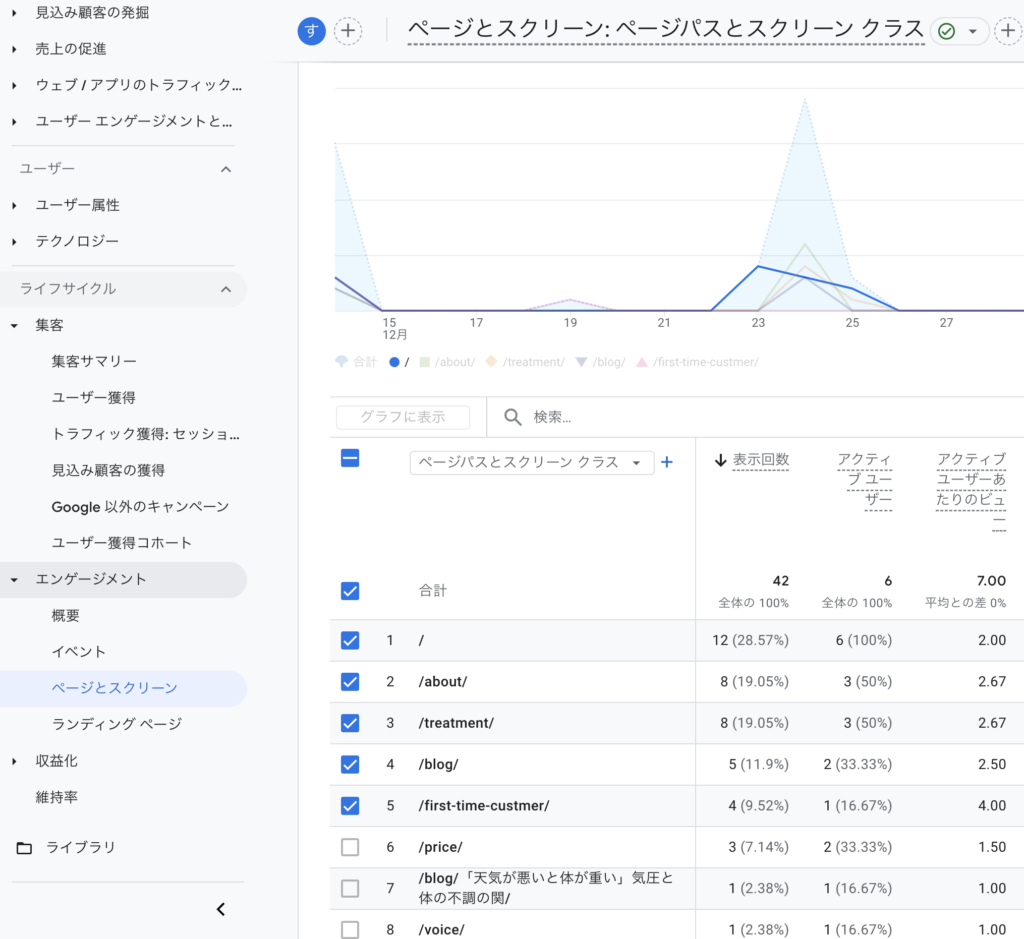
同画面で「/blog/」配下にフィルタをかけ、ブログ記事ランキングが見える状態
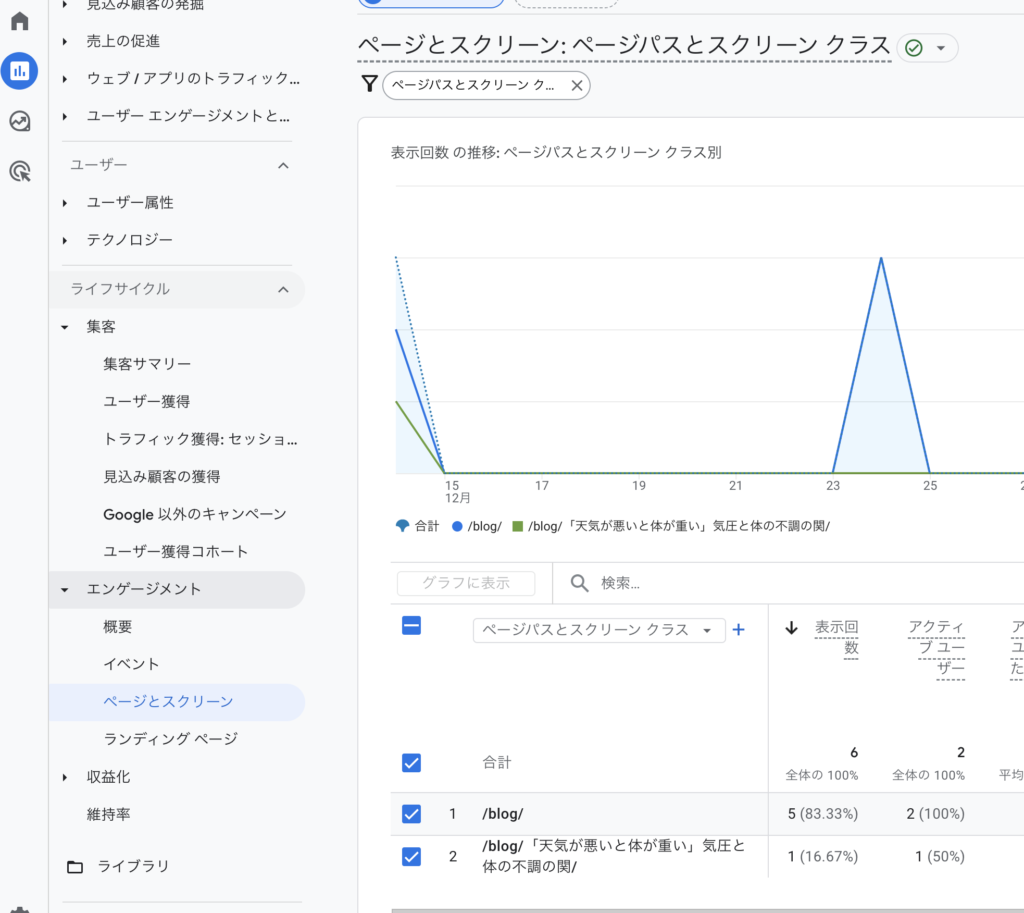
指標3:PV・ページ別PV(ミニノック4問)
問1(選択式:定義)
PVとして正しいのはどれ?
A. event_name=="page_view" の件数
B. session_id のユニーク数
C. event_name=="session_start" の件数
D. user_id のユニーク数
解答:A
解説: PVは page_view の回数です。
問2(記述:PVとユーザーの違い)
同じページで PVが多いがユニークユーザーが少ない場合、何が起きている可能性がありますか?(1〜2行)
解答例: 少数のユーザーが同じページを複数回見ている(フォーム入力で戻る、比較検討で見返す等)可能性。
解説: “人気”ではなく“迷い”や“再確認”の可能性もあるので、導線や内容の分かりやすさを疑います。
問3(実務:/contact/がPV上位の解釈)
ページ別PVで /contact/ が上位でした。最も適切な次の確認はどれ?
A. /contact/のPVが多い=成果が出ているので終了
B. /contact/到達は多いがCVが少ないなら、フォーム離脱(EFO)や入力負荷を疑う
C. /contact/をサイトから削除する
D. PVが多いページは全て成功
解答:B
解説: /contact/は終点になりやすいページ。到達が多くてもCVが増えないなら、フォーム周りの改善が最短です。
問4(実務:ブログPVから次に進む)
ブログ配下総PVが115で、記事別PV上位が分かりました。次に「成果につなげる」ために最優先で見るべきはどれ?
A. PVが多い記事だけ増やす
B. PV上位記事をランディングページとして見たときのCVR(指標4)
C. 画像を増やす
D. ページの色を変える
解答:B
解説: PV上位=成果ではありません。入口として機能しているかはLP別CVRで初めて判断できます。
指標4:初回訪問ベースのランディングページ別CVRを再現する(主役)
ビジネスの問い
- 初回訪問の入口(ランディングページ)別に、どこが予約(CV)につながっているか?
- “読まれている記事”と“成果につながる記事”は一致するのか?
Python集計ロジック(文章)
- 新規ユーザーの最初のセッションを取り出す
- そのセッション内の最初のpage_viewをLPとする
- セッション内にconversionがあればCV=1
- LP別に sessions / conversions / CVR(%) を出す
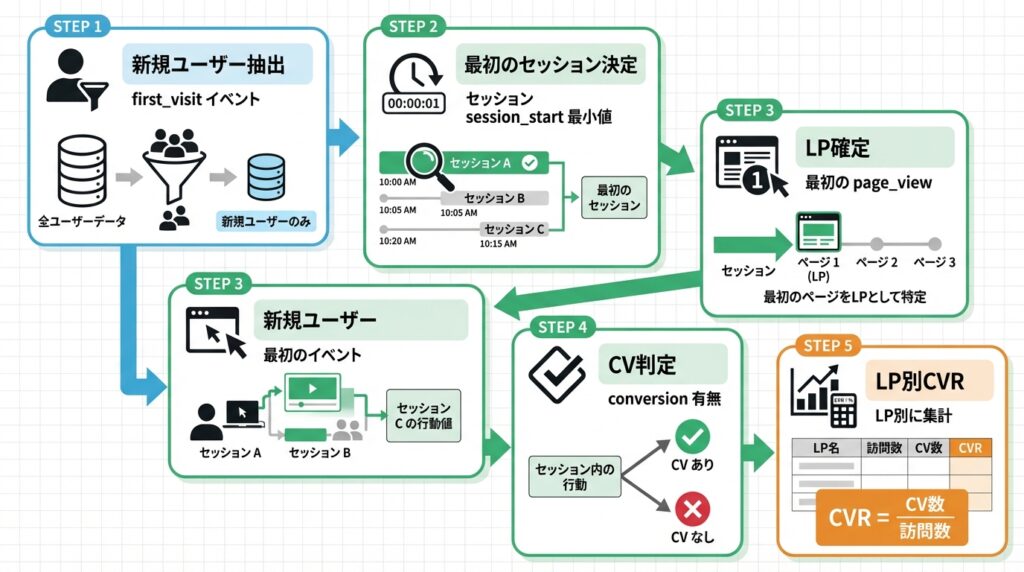
Pythonコード例
# 念のためソート(LP判定で最初のpage_viewを取りやすくする)
df = df.sort_values(["user_id", "session_id", "event_timestamp"]).reset_index(drop=True)
# 2) 新規ユーザー(first_visitを持つユーザー)を抽出
new_user_ids = df.loc[df["event_name"] == "first_visit", "user_id"].unique()
# 3) 新規ユーザーごとに「最初のセッション」を決める
# ※ session_start の中から、user_idごとに最小event_timestampのsession_idを採用
first_sessions = (
df[(df["event_name"] == "session_start") & (df["user_id"].isin(new_user_ids))]
.sort_values(["user_id", "event_timestamp"])
.drop_duplicates(subset=["user_id"], keep="first")[["user_id", "session_id"]]
)
# 4) 初回セッションのイベントログだけに絞る(初回訪問ベースの母集団)
first_session_events = df.merge(first_sessions, on=["user_id", "session_id"], how="inner")
# 5) 初回セッションの「ランディングページ(LP)」を確定
# セッション内で最初の page_view の page_path をLPとする
landing_pages = (
first_session_events[first_session_events["event_name"] == "page_view"]
.sort_values(["session_id", "event_timestamp"])
.drop_duplicates(subset=["session_id"], keep="first")[["session_id", "page_path"]]
.rename(columns={"page_path": "landing_page"})
)
# 6) 初回セッション内でCVが起きたか(0/1)を作る
# CVは conversion かつ /contact/ のみを対象(定義を明確化)
conv_sessions = (
first_session_events[
(first_session_events["event_name"] == "conversion")
& (first_session_events["page_path"] == "/contact/")
][["session_id"]]
.drop_duplicates()
)
conv_sessions["is_conversion"] = 1
# 7) LP×CV判定をセッション単位でまとめる
session_level = landing_pages.merge(conv_sessions, on="session_id", how="left")
session_level["is_conversion"] = session_level["is_conversion"].fillna(0).astype(int)
# 8) LP別に sessions / conversions / CVR% を算出
lp_cvr = (
session_level.groupby("landing_page")
.agg(
sessions=("session_id", "nunique"),
conversions=("is_conversion", "sum"),
)
.reset_index()
)
lp_cvr["cvr_pct"] = (lp_cvr["conversions"] / lp_cvr["sessions"] * 100).round(1)
# 見やすく:セッション数の多い順(またはCVR順でもOK)
lp_cvr = lp_cvr.sort_values(["sessions", "cvr_pct"], ascending=[False, False]).set_index("landing_page")
print("--- 初回訪問LP別CVRレポート(%表記) ---")
print(lp_cvr)結果(あなたの集計:%表記統一)
- /menu/acupuncture/:66.7%(ただし母数3)
- /blog/seo-basics/:25.0%(母数4)
- それ以外は0%が多い(CV総数が少ないため自然)
注意:sessionsが小さいLP(1〜2件)はCVRが跳ねるので参考値として扱う
ミニ対応表(GA4対応の書き込み欄)
- Python:初回セッションLP別に(セッション数・CV数・CVR)
- GA4:ランディングページ軸の「セッション」「コンバージョン」「セッションのコンバージョン率(相当)」
指標4:初回訪問ベースのランディングページ別CVR(ミニノック4問)
問1(選択式:定義)
初回訪問ベースのランディングページ(LP)の定義として正しいのはどれ?
A. ユーザー全期間で最初に見たページ
B. セッション内で最初に見たページ(session_id内の最初のpage_view)
C. PVが最も多いページ
D. /contact/ページ
解答:B
解説: LPは“セッションの入口”。初回訪問ベースでは「新規ユーザーの最初のセッション」に限定します。
問2(計算:基礎)
あるLPで初回訪問セッション数が4、CVが1ならCVR(%)はいくつ?
解答:25.0%
解説: 1÷4×100=25.0%。
問3(実務:高CVRだが母数が小さい)
/menu/acupuncture/ が sessions=3、CVR=66.7% と高い。最も妥当な判断はどれ?
A. すぐに広告費を全投入する
B. 良い兆候だが母数が小さいので、まずセッションを増やして再現性を確認する
C. たまたまなので必ず無視する
D. CVRが高い=全て正しいので検証不要
解答:B
解説: 母数が小さいとCVRは跳ねます。まず流入を増やすか期間を延ばし、同傾向が続くか確認します。
問4(実務:PV上位とCVRゼロのギャップ)
PV上位のブログ記事が、初回訪問LP別CVRでは0%でした。考えられる原因として適切なのはどれ?
A. その記事は読まれているが、予約導線(CTA・内部リンク)が弱い可能性
B. GA4が壊れている
C. ブログはすべて削除すべき
D. PVが多いならCVも必ず増えるはず
解答:A
解説: “読まれる”と“予約につながる”は別です。CTAの位置、予約ページへの導線、記事内容と施術メニューの接続が弱いとCVRは上がりません。
GA4のどのレポート・指標と対応しているか整理する
対応づけの考え方
迷ったら、次の3点で整理します。
- 何を数えている?(イベント or ユニーク)
- 単位は?(ユーザー / セッション / イベント)
- 率なら分母と分子は?(例:CVR=CV÷セッション)
対応表(例)
| 指標 | Pythonで数えるもの | GA4で見る系統 |
|---|---|---|
| ユーザー | user_idユニーク | 獲得(Acquisition) |
| 新規ユーザー | first_visitのuser_idユニーク | 獲得(Acquisition) |
| セッション | session_idユニーク | トラフィック獲得 |
| PV | page_view件数 | エンゲージメント(ページ) |
| LP別CVR | 初回セッションLP別にCV÷セッション | ランディングページ軸(標準or探索) |
まとめ:今回の学びを自分のGA4+Pythonにどう活かすか
まず自分のGA4で確認するチェックリスト
- ユーザー/新規ユーザー:獲得系
- セッション:トラフィック獲得系
- PV:ページとスクリーン(ページ別)
- LP別成果:ランディングページ軸(無ければ探索)
次にやる改善アクション例(さくら整体院の想定)
- CVRが出たLP(例:特定のブログ記事)
- 同テーマの記事を増やす、内部リンクで回遊を増やす、CTAを強化する
- PVはあるがCVが出ないLP
- 予約導線(/contact/)の誘導文、ボタン位置、フォーム入力(EFO)を見直す
- 流入別の違い
- Organicは獲得に強いが単発が多いなら、再訪導線(関連記事、メルマガ/LINE等)を設計する
自分のサイト版に置き換える手順
- page_pathを自サイトの構造に合わせて置換
- conversionイベントを自サイトのCV(予約完了/送信完了)に置換
- 同じロジックで集計し、GA4画面の数字と見比べる